
Linguistic Insights for Natural Language Understanding: Syntax and Constituency Parsing
Syntax and Constituency Parsing
Human language is incredibly complex and constantly changing. Yet, as fluent speakers of one or more languages, people are able to understand it almost implicitly.
Linguistics is the study of human language, which aims to describe its structure, meaning, and the way people use it in various contexts. When approaching a natural language understanding (NLU) task, such as intent classification, sentiment analysis, or question answering, popular deep learning architectures, such as LSTMs and Transformers, can do an impressive job. However, these approaches still have trouble with language phenomena that we as people understand without a second thought.
Applying linguistic theory can help us approximate human-level understanding of language to augment existing algorithms and architectures for NLU tasks. In this blog post, we’ll take one example as a case-study of what this application of linguistic theory might look like.
Let’s take a look at intent classification, which is often used by chatbots and virtual assistants to understand what a user is asking in order to give the correct response. Intent classification models are typically built to provide a single intent classification for each utterance. So, we would expect a model to classify the question “What time is it?” as a question about the current time in order to provide the current time to the user. But people don’t always break their sentences up into single intents. When speaking to a virtual assistant, you might ask “What time is it and when does the restaurant close?” Or when talking to Businessolver’s AI assistant, Sofia, in your employee benefits portal, you might say “I want to check my deductible, view my claim, and edit my son’s information.” A model that is trained to extract a single intent from a single sentence will never be able to give all the details that the user is looking for if it can’t identify all the questions that the user is asking in one utterance.
What we need is a model that can provide either a single intent classification, or multiple intents, if the user is asking more than one question. One way to do this would be to train an entirely new type of model that can output multiple intents. This could be a costly strategy if we don’t already have a labeled dataset of multi-intent utterances. Instead, let’s say we want to keep using a single-intent model we already have. We can apply linguistic theory by using syntactic parsing to augment the existing model.
To understand syntactic parsing, we first need to have a basic understanding of what syntax means in linguistics. Let’s take a step back from our intent classification example for a moment.
What is Syntactic Parsing?
Sentences are structured, that is, sentences aren’t just a bag of words that we can put in any order to create the same meaning. Consider the following two sentences:
- The dog bit the man.
- The man bit the dog.
These two sentences contain all the same words and the same part-of-speech tag order. The only difference is the order those words appear in. In this case, switching the positions of “dog” and “man” changes the subject and object of the verb “bit”, therefore changing the meaning of who was bitten, and who did the biting.
Syntactic structure also comes into play in determining the acceptability of sentences in a language. For example, if you’re a native speaker of English, you probably agree that example c. below isn’t a grammatical sentence:
- Dog the bit man the.
Once again, this sentence contains all the same words as the sentences in a. and b. but the order of those words violates our mental grammar rules for English. By documenting those mental rules, linguists are able to create grammars, which we can then use to annotate the structure of a sentence.
In this context grammar means something a bit different than what we are taught in elementary school. Grammars in linguistics are not used to tell speakers how to use language (e.g. “Don’t split your infinitives!”). Instead, grammars are used to describe how speakers use language naturally. For example, we can learn from observing speakers of English that noun phrases such as “the dog”, “the man”, “her sister’s friend”, or “it” can occur in the same place in a sentence. Take the sentences below as an example:
- The dog ate the treat.
- The man ate the treat.
- Her sister’s friend ate the treat.
- It ate the treat.
Although all four of these sentences have different meanings, we can see that the four noun phrases we described above can all fulfill the same part of the sentence’s syntactic structure – in this case, they are all the subject of the verb “ate”. Notably, regardless of the length of these noun phrases, they function as a single unit in the structure of a sentence. This property of a phrase functioning as a single unit in a sentence is called constituency.
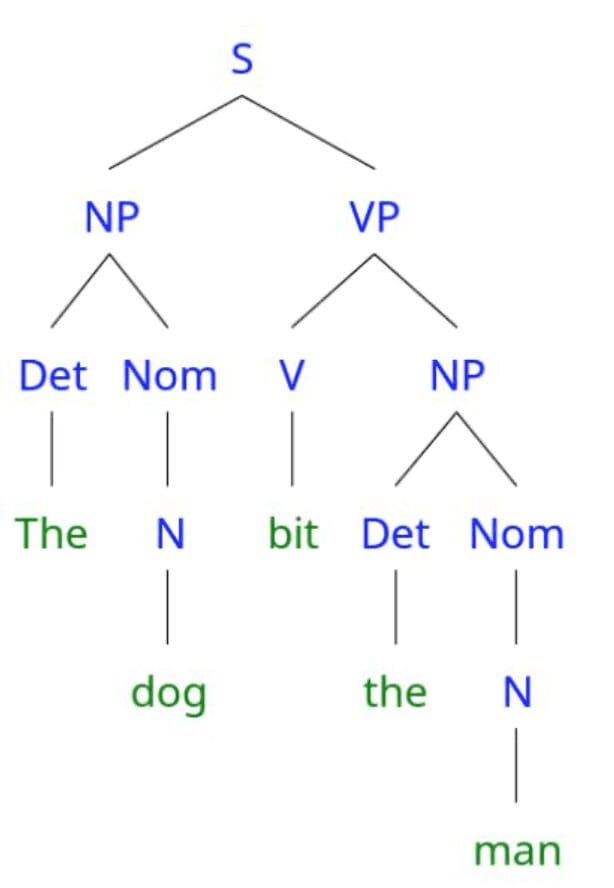
Constituents aren’t restricted to noun phrases. Sentences can contain verb phrases (e.g. “bit the man”), prepositional phrases (e.g. “near the bed”), adverbial phrases (e.g. “sleepily”), etc. We can create grammars by writing rules that describe how words can be combined to form constituents and sentences. Take a look at the parse tree for the sentence “The dog bit the man” below, and then we’ll discuss the grammar that was used to create that tree.
It might not be immediately clear what all the labels and lines mean in this parse tree – we’ll get to those in a moment. First, let’s think about the constituents in this tree. A constituent in a parse tree is defined as all the words that share one ancestor node. We discussed earlier that “the dog” is a noun phrase constituent. Notice that the words “the” and “dog” share an ancestor node “NP” (noun phrase). Similarly, we can see that all of the words in the verb phrase constituent “bit the man” share an ancestor node VP (verb phrase). We can also use this tree to see what isn’t a constituent. For example, the word sequence “the dog bit the” is not a constituent because although they share a common ancestor node S (sentence), that S node is also an ancestor of the word “man”. In other words, “the dog bit the” is not a constituent because it does not include all of the words under the shared ancestor node.
Now that we’re starting to understand how to identify constituents by looking at a tree, let’s look at the grammar that was used to create this parse tree. The grammar below is a very small toy example of a grammar that might be used to describe the structure of a limited number of sentences in English.
S (Sentence) à NP VP
NP (Noun phrase) à Det Nom
Nom (Nominal) à N Nom | N
VP (Verb Phrase) à V NP
N (Noun) à cat | dog | man | woman | person
V (Verb) à bit | bites | licks | licked
Det (Determiner) à the
In this notation, the symbol on the left side of the arrow (called a non-terminal symbol) can be formed by the element(s) on the right side of the arrow. For example, a sentence (S) can be formed by the combination of a noun phrase (NP) preceding a verb phrase (VP). The pipe symbol (|) means “or”, so a nominal (Nom) can either be formed by a noun (N) followed by a nominal, or by a noun alone. Notice that some rules just have a list of words on the right side of the arrow. Words are called terminal symbols because they only occur at the leaves (i.e., nodes that do not have any children) of the parse tree. In most cases, the symbol on the left side a rule with a single word symbol on the right is the same as the part of speech tag for that word.
Using this grammar, let’s build the parse tree we saw above. There are multiple ways to build a parse tree, but for the sake of simplicity, we’ll build this one from the bottom up. First, we look at the words in our sentence “The dog big the man” and see what rules we can apply. It looks like all of the words have a corresponding rule that gives a label to that single word. Let’s draw those labels:
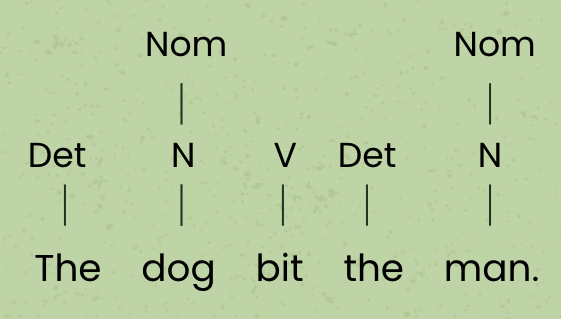
You may notice that we added two labels to the nouns in the sentence – first the noun label, then the nominal label. While an important distinction in linguistics, for our use case, we can assume nouns and nominals are essentially the same category.
Now that we have labels above each word resulting in a sequence of labels – Det, Nom, V Det, Nom – we can look at our grammar again to see what rules might apply to the sequence of labels. Because we have the sequence “Det Nom”, we can apply the NP à Det Nom rule. In fact, we can apply this rule twice, since there are two “Det Nom” sequences in our sentence:
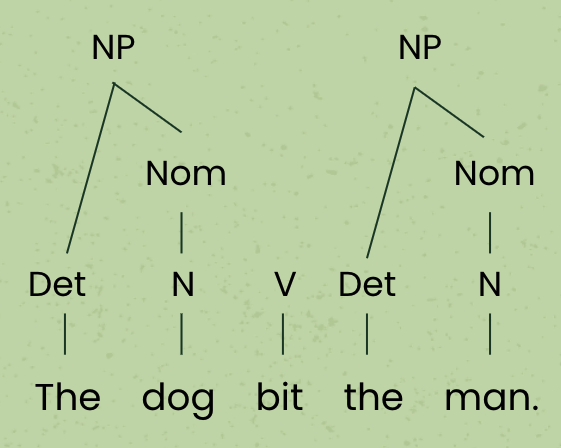
With this rule, we have formed two new noun phrases, and our node label sequence now reads: NP, V, NP. The order of symbols on the right side of a rule matters when applying a grammar. So while there is no rule in our grammar that forms a constituent out of the sequence “NP V”, there is a rule that forms a constituent out of the sequence “V NP”: VP à V NP. Therefore we can add a new VP node and connect it to the children nodes V and NP:
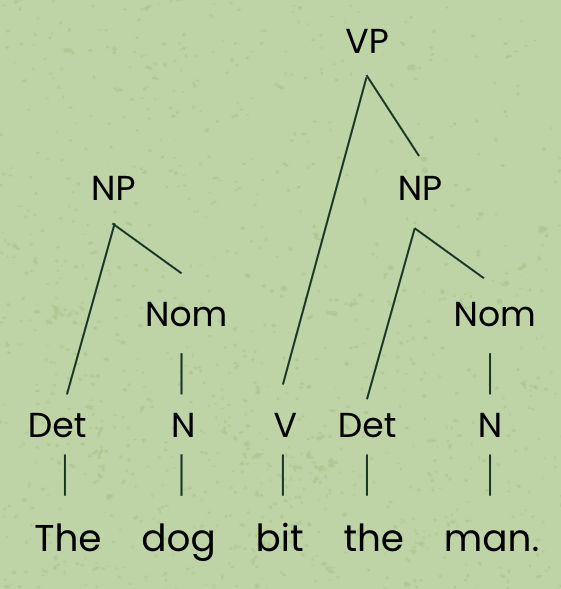
Finally, we just have two nodes in our label sequence: NP, VP. This is exactly the label sequence we need to fulfill the rule in the grammar that forms a sentence: S à NP VP. Adding that node, we arrive at our final parse tree:
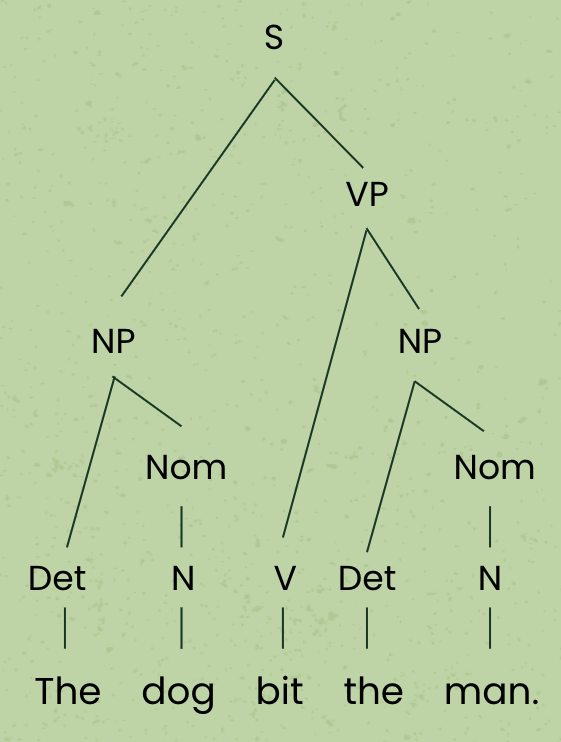
We know that we are done parsing the sentence because we now have only a single node at the top of the tree, and there are no lower nodes that are disconnected from a tree – they all have a parent node. Furthermore, the single node we are left with is an S node, so we know we have created a sentence structure that fits the string of words we started with.
It’s important to note that this is a very simplified example of a constituency parse tree. There is lots more to learn on this topic, including different frameworks for parsing (such as x-bar, minimalism, HPSG, for your Googling pleasure) and different syntactic theories that inform the rules in a grammar and the resulting tree structure. There are also completely different ways to parse a sentence, such as dependency parsing, which focuses on the grammatical relationships between individual words (e.g., subject, object, modifier, etc.), rather than relationships and structures of whole constituents. Each of these avenues for annotating the structure of a sentence may lend themselves to different NLP applications. In this blog post, let’s stick to our intent classification example and see how even this simple understanding of constituency parsing can augment an NLU system.
Applying Syntax to NLU Systems:
Recall the conversation with Sofia, our virtual benefits assistant, that we discussed above. We wanted the NLU model to understand the question “I want to check my deductible, view my claim, and edit my son’s information.” The user is asking about three different tasks; “check my deductible,” “view my claim,” and “edit my son’s information.” In this instance we can see that those three tasks are part of a list, where each of the list elements introduces something that the user wants to do. We know this because the list is preceded by the phrase “I want to.” So, how can we use constituency parsing to help us solve this problem? Let’s look at the parse tree for this sentence:
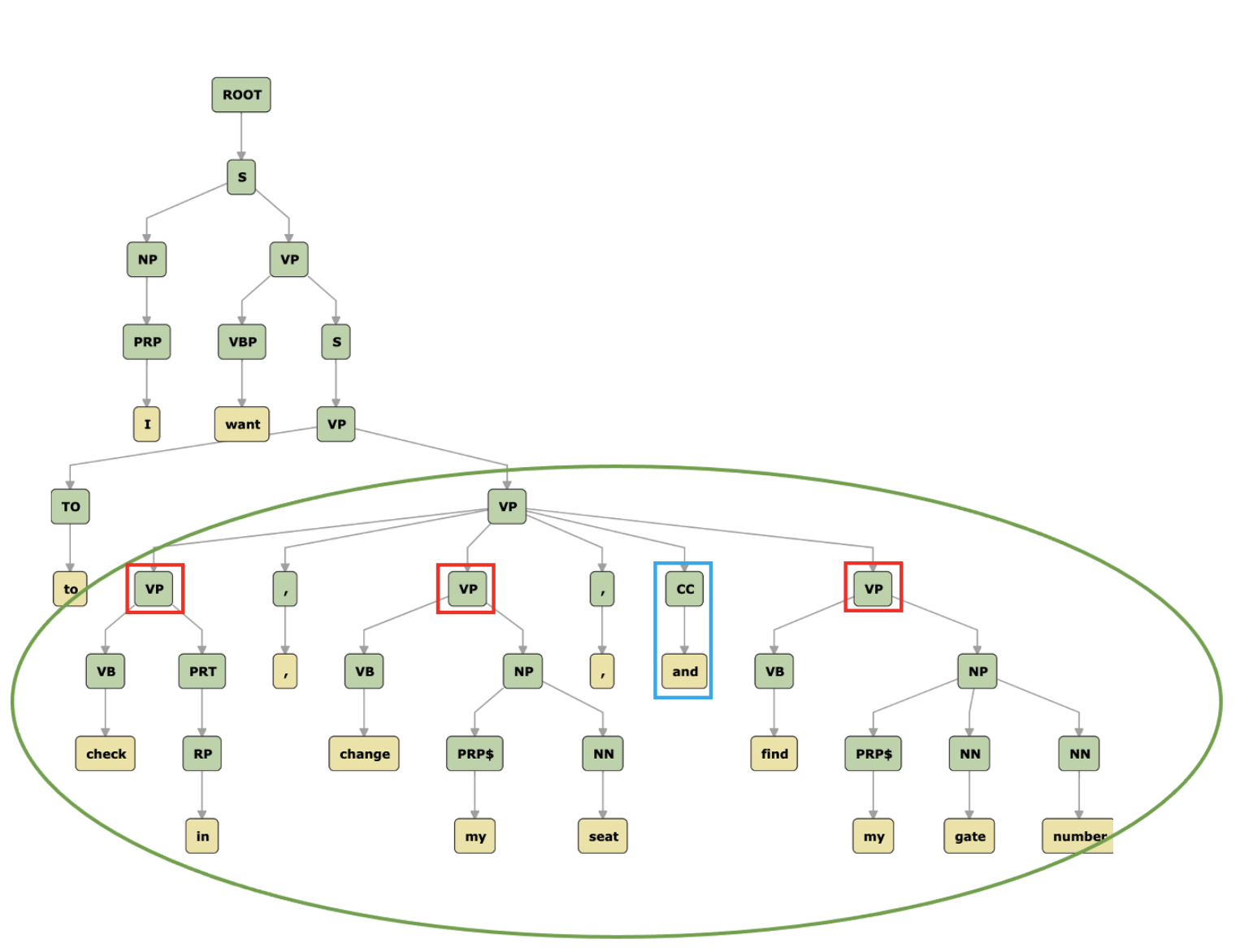
This tree looks a bit different than the examples we’ve seen before, but the basic idea is the same. (It was produced by Stanford CoreNLP’s constituency parser, which you can read more about. The labels are slightly different as well, since its grammar is based on the Penn Treebank, which uses its own tagset.)
The top of the structure of this sentence looks almost identical to our previous example – there is a sentence (S) that is formed by a noun phrase (NP) followed by a verb phrase (VP). The verb phrase in this sentence just happens to be a bit more complex than the one we saw before. One part of that complexity is the presence of a coordinate verb phrase – that is, a verb phrase that is made up of two or more other verb phrases (three other verb phrases, in this case). We can visually identify this coordinated verb phrase (circled in green in the tree above) by the presence of more than one child constituent and the presence of a coordinating conjunction, CC (in this case “and”). The elements that are being coordinated are the VPs identified by the red squares. They are the children of the topmost VP inside the green circle, excluding the punctuation and coordinating conjunction. If we look at each of these coordinated verb phrases, we see that they are exactly what we were hoping to identify – the three different requests that the user is making – “check my deductible,” “view my claim,” and “edit my son’s information.”
If our NLU system has access to the parse tree for this sentence, we could use our knowledge of the structure of a coordinate phrase in order to extract the three requests that the user is making.
How Will Sofia Use Syntax?
In the case of Businessolver’s virtual assistant, Sofia, we are working on ways to implement this parsing in our intent recognition, so that Sofia can understand when users are asking multiple questions at once. Ideally, we would like Sofia to be able to say “I understand you want to talk about your deductible, your claims, and your dependent. Which would you like to start with?” The user can then choose which topic to tackle first, and Sofia will prompt the user to return to the other topics later on in the conversation.
To do this, our syntax-based list extractor will need some additional work. Although constituency parsing can reliably help us extract the elements of a list, we don’t have any guarantee that those elements actually correspond to separate topics, as defined by our intents.
For example, in the sentence “I checked my deductible, and viewed my claim, but I don’t see where to change my son’s information” we would probably extract the list elements “checked my deductible” and “viewed my claim.” But the user is really asking about their son’s information. There are a few ways we might mitigate this issue, with one possibility being looking for cues that indicate a list is talking about multiple topics, such as a list preceded by the words “I want to.” Another possibility would be looking at the conjunction that joins the list element. We might find a pattern that shows that we should treat lists joined by “but” differently than lists joined by “and.” Although building this set of rules will take time, because the rules are based in linguistics and our analysis of real examples, we can be confident that they will reliably produce the correct output.
Hopefully, this example gives you a taste of how constituency parsing can be useful in NLU tasks. To summarize: Because the syntax of a sentence is so closely tied to its meaning, we can use that structure in creative ways to help artificial intelligence applications understand language more closely to the way people do. This can be particularly helpful in augmenting neural-based approaches, which are often a “black box.” That is, we don’t know what features or patterns the model is using to make its decisions, so we can’t always predict how it will get things wrong. Adding a layer of rule-based syntactic logic can be one way to mitigate that risk and use human understanding of sentence structure to teach computers how to process language.
If you would like to learn more on the topic of syntax and syntactic parsing, Speech and Language Processing by Jurafsky & Martin has several chapters that give a good introduction to topics like constituency grammars, constituency parsing, and logical representations of sentence meaning.